Contents
- 1 Would you trust the information presented in this article?
- 2 Is this article written by an expert or enthusiast who knows the topic well, or is it more shallow in nature?
- 3 Does the site have duplicate, overlapping, or redundant articles on the same or similar topics with slightly different keyword variations?
In 2011, Google bombed the SEO community with the first iteration of Panda. When unveiled, it affected 12% of search results. No one knows exactly what specific points that Panda was meant to target (unless they happen to be a Google engineer). However, we can glean details from Google’s article: More guidance on building high-quality sites. You can gather from the title alone that Panda was meant to target low quality sites. The question is — What does Google use to determine whether a site is high quality or low quality?
Google presents 23 questions to ask yourself, so you can self-assess whether your article is worthy, or likely to be struck down by Panda. Below is the list of questions that would supposedly free your site of penalties, if you could answer them in the affirmative. After listing, I will give some background story about Google patents and other events that can shed some light on what these questions are driving at.
Would you trust the information presented in this article?

This first point is obviously focused on trust. How does Google know whether your page is trusted or not? One could be HTTPS — Google has declared that as a positive ranking factor.
Another is to know who the author is — Google’s Eric Schmidt claimed that by using a constellation of online profiles, Google could derive an “author rank” for an individual, with a higher ranked profile obviously being more trusted, and where anonymous articles are made irrelevant.
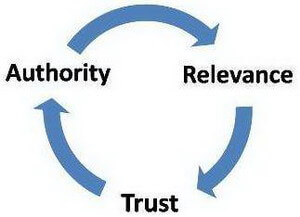 Majestic has a topical “trust flow” factor, which attributes trustworthiness of various sites as pertaining to a particular niche. Likewise, Google has a patent which throws out pages that link to your site if they’re not trusted (because they’re associated with you by IP, share the same outgoing links, or have the exact same content context — in other words, a low quality private blog network was identified as belonging to the same owner as the site).
Majestic has a topical “trust flow” factor, which attributes trustworthiness of various sites as pertaining to a particular niche. Likewise, Google has a patent which throws out pages that link to your site if they’re not trusted (because they’re associated with you by IP, share the same outgoing links, or have the exact same content context — in other words, a low quality private blog network was identified as belonging to the same owner as the site).![]()
Ways to provide evidence of trust to Google: Move your domain to HTTPs, start developing social accounts to build author rank and link that author rank to your site, and be cautious when using private blog networks so as not to give Google reasons to distrust you. While I could certainly elaborate on trust far more, I’ll save that for other points below, which also focus on the trust issue.
Is this article written by an expert or enthusiast who knows the topic well, or is it more shallow in nature?
Here again is the concept of “author rank”. How else could Google possibly determine whether an article was written by an “expert or enthusiast who knows the topic well”? Matt Cutts went on record saying that Google was using a form of author rank as of that March 2014 article, and “discussed the development in a 2013 interview”.
To make a determination that an author knows a topic well, Google could be assigning a topical influence to the blogs maintained by that author (even across multiple domains). Klout does this, and majestic.com has been assigning a topical authority trust to various domains for a while now. It would only make sense to acknowledge that Google has the resources to be able to do a far better job of assigning a topical trust to various articles, and attaching that trust to the author who wrote them.

How Klout Measure Social Influence
Ways to provide Google evidence that your articles are written by an expert: Sign up to Facebook, LinkedIn, Twitter and Google+. Link those to your blog, and your blog to those social accounts. You could even sign up for Klout and start participating on the 13 different platforms they monitor — that would help you with Bing, as well as Google, because Klout has a relationship with Bing for promoting articles based on an author’s Klout score. Building a Klout score no doubt does everything necessary to satisfy Google’s author rank algorithm.
Does the site have duplicate, overlapping, or redundant articles on the same or similar topics with slightly different keyword variations?
This here caused a ton of damage to webmasters. First, let’s talk about “duplicate” articles. I’m going to assume most people know the perils of having duplicate content on their site is a bad thing. You should keep in mind that WordPress is horrible for injecting duplicate content into a site. By creating an article, giving it 5 tags and clicking submit — you could be creating 9 pages of duplicate content! With default settings, WordPress creates the homepage, the article, 5 pages for tags, one for category, and one for archives by date. Check out our on-page SEO optimization for WordPress article to get that under control.
The remainder of the sentence is where the bulk of the bad stuff happened for blackhat SEOs. Taken note of these words — “overlapping, redundant, similar topics with slightly different keyword variations”. Each of these need an explanation.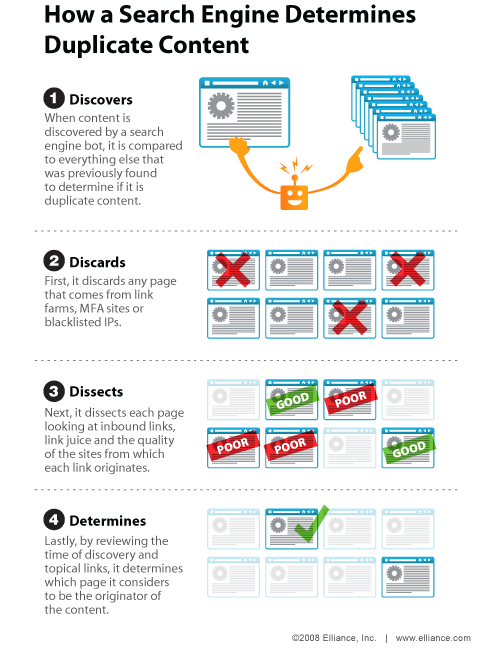
Overlapping:
Does Google know whether you’re writing about topics that overlap too much? Yes, they do. I’ll go into this in detail by discussing Google’s low quality site patent below.
Redundant:
Your article isn’t making any new point. It’s simply saying the same thing as many other pages on the internet. It was likely re-written from someone else’s page, using different words to say the same thing. In other words, it’s redundant. Can Google determine this? Yes. Again, I’ll explain this more below with Google’s low quality site patent.
Similar topics with slightly different keyword variations:
 This is article spinning. Article spinning is where someone takes an article, and finds synonyms (different keyword variations) and outputs an article, each time with a random variation of a keyword. The end result is you get an article that says exactly the same thing — dozens, hundreds, or thousands of times — but in reality it’s saying exactly the same thing, making all the same points. Here, Google is saying that article spinning will get your site in trouble with Panda. Can Google find article spins? Yes they can.
This is article spinning. Article spinning is where someone takes an article, and finds synonyms (different keyword variations) and outputs an article, each time with a random variation of a keyword. The end result is you get an article that says exactly the same thing — dozens, hundreds, or thousands of times — but in reality it’s saying exactly the same thing, making all the same points. Here, Google is saying that article spinning will get your site in trouble with Panda. Can Google find article spins? Yes they can.
I’ve written an article about Google’s low quality sites patent, so I’m not going to completely go in depth here. I will give a broad overview of what Google claims it can do, via the patent.
The patent states:
“To determine the link quality score, the link engine can perform diversity filtering on the resources. Diversity filtering is a process for discarding resources that provide essentially redundant information to the link quality engine.”
Google uses “diversity filtering” to make pages that are not diverse worthless for the purpose of ranking, or providing benefit in the form of a backlink.
Google says they can do this, but how do they do this? Following is another quote from the patent:
For example, the system can determine that a group of candidate resources all belong to a same different site, e.g., by determining that the group of candidate resources are associated with the same domain name or the same Internet Protocol (IP) address, or that each of the candidate resources in the group links to a minimum number of the same sites. In another example, the system can determine that a group of candidate resources share a same content context. A content context is a characterization of the content of a resource, e.g., a topic discussed in the resource or a machine classification of the resource.
In other words, if content comes from the same IP address, or the content links to the same pages with outbound links, or the page shares a same content context, then the article has been determined to be not diverse enough, and will neither rank, nor pass link benefit to help another page rank.
What can be done to satisfy this 3rd point of Google’s Panda algorithm? All content on your site needs to be diverse. It needs to make points not made in the same way by any other page on the internet. Simply hiring someone to rewrite someone else’s article will trip the diversity filter, so that type of content is worthless. Needless to say, if you’re article spinning — you better have an extremely diverse spin if you expect it to provide benefit for ranking or link benefits from a private network blog.
We’ve covered 3 points so far, there are 20 more! Continue to read more about how you can avoid Google Panda penalties.

Comments